
ETL은 단순히 “테이블 데이터를 이관 한다” 라고 생각 할 수 있습니다. 이기종 시스템간의 상호 데이터 마이그레이션으로 생각 할 수 있습니다. 반면에 상당히 복잡한 설계 (만든이의 의도를 알 수 없는) ERD를 이행 할 수 도 있습니다. 이때 데이터의 누락이나 이행 오류가 발생이 된다면 수치에 대한 오류가 발생할 것이고 이에 대한 오류를 찾는 것은 매우 많은 시간과 공을 들여야 합니다. 때문에 ETL은 표준화된 개발 프로세스와 운영이 반드시 필요하게 되었습니다.
ETL 은 분석/설계를 거쳐 개발/테스트/운영/안정화의 프로세스를 수행해야 합니다. (오픈, 운영 , 데이터 보정) 잘못된 설계와 데이터 이행이 지속적으로 누적되고 운영된다면 그 에 따른 막대한 유지보수 비용이 발생하게 됩니다. 그리고 ETL 개발 경험상 운영 시스템에서는 데이터 값, 품질, 검증, 변환 규칙 등은 최초 ETL 개발자의 설계를 초과 할 가능 성이 크기 때문입니다. 따라서 표준화된 개발/운영 프로세스야 말로 이러한 사고를 줄일 수 있습니다.
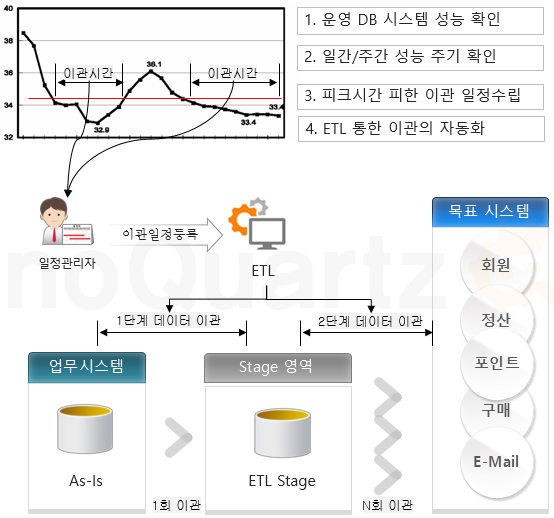
ETL 개발자들은 ETLJob의 확장성과 성능 개선 방향을 고려해야 합니다. 서비스는 지속적으로 개선 되거나 통합될 것이며 그에 따른 데이터의 양은 지속적으로 증가 할 것 이기 때문입니다. 즉 누적되는 데이터의 양 을 고려해야 합니다. 또한 기존 시스템의 성능과 네트워크 인프라 구성에 대한 성능 최적화를 고려해야 하고 Fail Over 정책도 구상해야 합니다. Scale out과 시스템 자원도 고려하여 아키텍처를 구성 해야 하는 비용 또한 고려 해야만 합니다.
댓글 0
| 번호 | 제목 | 조회 수 |
|---|---|---|
| 6 |
모던 ETL
| 350 |
| 5 | ETL Vender | 106169 |
| 4 |
성능에 대한 고려
| 22449 |
| » |
ETL 도전 과제
| 2300 |
| 2 |
ETL 단계별 역할
| 4087 |
| 1 |
ETL 이란?
| 59423 |