
Extract
ETL 파트의 첫번째 처리 기능으로 소스시스템에서 데이터를 추출 합니다. ETL에 가장 중요한 부분으로서 후속 프로세스를 위해 제대로 된 데이터 추출이 필요 합니다.
대부분의 DW 이행 프로젝트는 서로 다른 소스 시스템을 고려 하고 있습니다. 각각의 분리된 시스템은 서로 다른 정책과 포맷으로 분리 되어 있습니다. 공통 데이터 소스 포맷들은 관계형 데이터베이스 또는 XML, Flat 파일등을 포함하고 있거나 비관계형 데이터베이스 구조 (예를 들어 IMS), 또는 가상화 스토리시(VSAM) , (ISAM) 등일 수도 있습니다.
또한 중간에 데이터 저장 장치가 필요하지 않은 경우 즉석에서 그 추출 된 데이터 소스 및 스트리밍 로드 ETL을 수행 하는 방법도 있습니다.
일반적으로는 추출 단계 중 변환 처리를 위해 시나리오와 계획을 수립 합니다. 이관 후에 다시 데이터 형식을 변경 하려면 거의 동일한 리소스를 소모 하게 됩니다.
추출의 본질적인 부분은 소스에서 가져온 데이터 (예 : 패턴 / 기본 또는 값의 목록 등) 특정 도메인의 데이터 유효성 검사를 포함합니다. 데이터 검증에(규칙/패턴) 실패하면 전체 또는 부분적으로 ETL을 실패 하게 됩니다. ETL은 짧게는 1~2분 많게는 24시간 이상도 시스템이 수행을 하게 됩니다. 실패 했을경우 어떤한 식으로 롤백을 할 것인지, Fail 데이터를 찾아서 해당 데이터만 ETL할것인지를 데이터구조를 분석한 후 초기 계획에 수립하여야 합니다. 보통은 이렇게 사람이 직접 할 수 없는 또는 단순하지만 자원이 많이 소요되는 비생산적인 업무를 대신할 Tool을 가지고 ETL 프로세스를 수행합니다.
한번 구축된 시스템은 언젠간 통/폐합이 될것입니다. 통합될 미래의 사항을 시스템 구축 당시 고려하기는 매우 힘듭니다. 따라서 효율적인 업무 프로세스와 유지보수, Fail over 정책을 수립 하기 위해 표준화된 ETL을 개발 모델을 설계 해야 합니다.
Transform
데이터 변환 영역에서는 목표 시스템에 데이터를 로딩(이관)하기 전에 필요한 규약과 기능에 대해 정의를 합니다. 가끔 변환 정책이 전혀 필요 없을 때도 있습니다. 그런 데이터들을 1:1 매핑 또는 ‘pass through’ 라고 도 합니다.
데이터 변환에서 가장 중요한 부분은 목표 시스템으로 이관 전에 데이터를 클렌징 하는것 입니다. 즉 DQ(Data Quality)를 지정 하는 것과 규약을 정의 하는 부분입니다.
ETL 작업 중 70% 가 이 영역에 있습니다. Transform을 어떻게 설계하고 구현 할 것을 고민할 지가 ETL 개발자와 사용하는 툴에 의해 결정이 되며 ETL 성공과 운영에 매우 중요한 위치를 차지 합니다.
-
데이터 클렌징
- Asis 시스템의 데이터를 필터링 하여 쓰레기 데이터를 걸러 냅니다. 이러한 작업을 생략하고 ETL을 진행 하면 신규 또는 Tobe 시스템 까지 쓰레기 데이터가 이관됩니다. 이러한 작업은 작업자의 역량에 의존 하고 있습니다. 최근엔 DQ 시스템을 도입하여 표준화를 수립 한 후 ETL을 수행합니다.
-
통신 데이터 규약
- 다른 시스템과의 상호 작용을 하기 위해 당면한 과제는 서로에 대한 통신 규약 입니다. 캐릭터 셋의 경우 한 시스템에선 가용 하나 다른 시스템에서는 불가능 할 수도 있습니다.
-
기타 비지니스/기술 적 이슈에 따른 데이터 변환 유형
- 조건(Where) 이관
- 특정 컬럼 이관
- 코드 변환 이관 (예를 들어 102, 103… 등을 A02, B03으로 데이터 자체 변환)
- 산술 계산 로직 변환 ( 수량, 단가 이관 시 총 금액을 계산 하여 신규 컬럼 total_price에 이관)
- 집합 통계 결과 계산 이관
- 정렬 기준 변환
- 중복 및 null 제거(DQ)
- 키 생성 및 키 변경 이관 (대리키, 자연키 등..)
- 정규화 또는 비정규화 작업
- 컬럼 분리
- DB Table 튜닝을 위한 참조 파일 탐색
- 데이터 정규화 등
Load
적재 단계에서는 추출하고 변형된 데이터를 Flat 파일이나 DW 또는 RDB으로 데이터를 로드 하는 단계 입니다. 조직의 요구 사항에 따라 이 프로세스는 매우 다양합니다. 기존 정보를 Overwrite 하던가 데이터가 없으면 Insert를 하거나 존재하면 Update를 수행을 하기도 합니다 또한 이런 일련의 ETL 프로세스를 스케줄러에 의해 주기적으로 관리 되기를 바라기도 합니다. 매 분, 매 시, 매일 주 단위 월 단위로 데이터를 계산하거나 산출하여 저장이 필요하기 때문입니다.
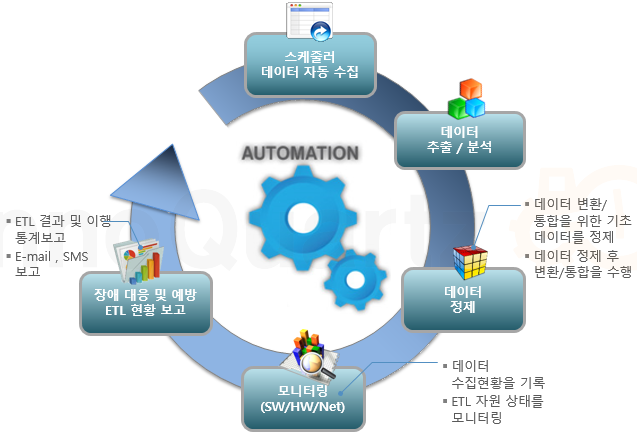
또는 5분 ,1시간, 6시간 간격으로 도 ETL수행을 요구 하기도 합니다. 그 밖에 스케줄러의 기능에 따라 월요일, 매주 토요일 6시 또는 매월 28일 등등의 스케줄이 필요할 때도 있습니다.
ETL 적재 단계는 목적 시스템과 상호 작용함으로서 고유성, 참조 무결성, 필수 필드에 대한 트리거 프로세스등이 전체 데이터 품질과 성능에 기여 합니다.
예를 들어, 금융 기관은 여러 부서에서는 고객에 대한 정보를 가질 수 있으며 각 부서는 고객의 정보 커스트 마이징하거나 다른 방식으로 보관 또는 나열 할 수 있습니다. 회계 부서 번호로 고객을 나열 할 수 있는 반면 회원 부서는 이름으로 고객을 나열 할 수 있거나 이벤트 부서는 회원의 여러 기준의 실적을 판단이 필요 할 수 있습니다. ETL로 인해 데이터 요소의 모든 번들 및 데이터베이스 또는 데이터 창고에 저장하는 것처럼, 균일 프리젠테이션영역으로 통합 할 수 있습니다. 즉 원 데이터는 변경 없이 데이터가 필요한 형태로 DW에 적재하여 각 이기종 시스템별로 최적화된 Data 를 제공 할 수 있습니다.
ETL을 사용하는 또 다른 방법은 영구적으로 다른 응용 프로그램 정보를 이동 시키는 것입니다. 즉, 차세대 Asis Tobe 시스템 구축, 신규 데이터 구축 시 새로운 응용 프로그램에 System Integration을 수행 할 수 있습니다
댓글 0
| 번호 | 제목 | 조회 수 |
|---|---|---|
| 6 |
모던 ETL
| 350 |
| 5 | ETL Vender | 106169 |
| 4 |
성능에 대한 고려
| 22449 |
| 3 |
ETL 도전 과제
| 2300 |
| » |
ETL 단계별 역할
| 4087 |
| 1 |
ETL 이란?
| 59423 |